
Introduction
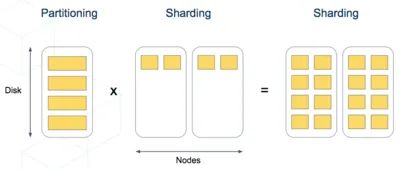
As the demand for scalable and efficient data management grows, database architects must choose appropriate techniques to handle ever-increasing data volumes. Two commonly used methods are sharding and partitioning, both of which divide large datasets to improve performance and maintainability. While they share similarities, their fundamental differences play a critical role in determining which technique to adopt. Drawing insights from the book Designing Data-Intensive Applications (particularly the partitioning chapter), this article provides a comprehensive and unique perspective on sharding and partitioning, including complex real-world scenarios.
What is Sharding?
Sharding, or horizontal partitioning, is a technique where data is distributed across multiple servers (or nodes), each hosting a subset of the data. This distribution leverages a shard key to determine the location of specific data. Sharding is especially effective in scaling applications horizontally by adding more servers to handle increased traffic and data.
How Sharding Works
Imagine a global e-commerce platform with millions of customers and transactions. To ensure low latency and high availability, sharding can be implemented by distributing user data based on geographical regions. For instance:
- Shard 1: Users in North America
- Shard 2: Users in Europe
- Shard 3: Users in Asia
To achieve this, the system uses a shard key such as country_code / region_id to determine which shard stores a particular user’s data. When a user logs in, the shard key allows the system to quickly route the request to the appropriate server.
Advanced Sharding Example: Combining Region and User Activity
A basic regional sharding strategy might lead to unbalanced data distribution due to varying user populations. To address this, consider a hybrid approach that combines geographical and activity-based factors:
- Active users are sharded separately for faster access.
- Inactive users are grouped into archival shards by their last activity date.
This strategy ensures that heavily queried data is optimized for performance, while less-accessed data remains stored efficiently.
What is Partitioning?
Partitioning refers to dividing a single table into smaller, manageable parts within the same database instance. Unlike sharding, partitioning does not involve distributing data across multiple servers. Instead, the table is split into logical or physical segments, which can improve query performance and streamline maintenance tasks.
Partitioning Techniques
- Range Partitioning: Divides data based on a continuous range of values. For example, a table storing transaction logs could be partitioned by date.
- List Partitioning: Segments data based on discrete values, such as user roles or product categories.
- Hash Partitioning: Uses a hash function on a key column to evenly distribute data across partitions.
Complex Partitioning Example: Combining Range and Hash Partitioning
For a time-sensitive IoT application storing sensor data:
- Use range partitioning to group data by month.
- Within each month, apply hash partitioning to evenly distribute data across multiple physical storage units based on the sensor ID.
This combination reduces query scope for time-based searches while balancing load across storage units.
Combining Sharding and Partitioning
In certain scenarios, combining sharding and partitioning is necessary to achieve optimal scalability and performance. Consider a global video streaming service with billions of users and petabytes of data:
- Sharding: Distribute user accounts across geographical regions (e.g., North America, Europe, Asia).
- Partitioning: Within each region’s shard, partition video data by genre or upload date.
This hybrid approach allows for efficient query execution and maintenance at both regional and local levels.
Challenges and Best Practices
| Category | Details |
|---|---|
| Sharding Challenges |
|
| Sharding Best Practices |
|
| Partitioning Challenges |
|
| Partitioning Best Practices |
|
Conclusion
Sharding and partitioning are indispensable tools for scaling and optimizing database systems. While sharding excels in distributing data across multiple servers to handle massive user traffic, partitioning enhances query performance and maintenance within a single database instance. In part 2, we will look at a sensor-like case study to see how we can utilize partitioning for such data.